Šāda pieeja patlaban jau ir izplatīta metode, lai atklātu krāpšanas mēģinājumus uzņēmumu līmenī (skatīt, piemēram, Cecchini u. c. (2010), Ravisankar u. c. (2011), West, Bhattacharya (2016)). Galvenā ideja – trenēt algoritmu ar mērķi nošķirt uzņēmumus, kuri ievēro likumus, no tiem, kuri izvairās no nodokļu nomaksas, pamatojoties uz novērojamām uzņēmumu pazīmēm. Tāpat kā jebkura finanšu manipulācija, arī izvairīšanās no nodokļu nomaksas “atstāj pēdas” uzņēmumu bilancēs. Cilvēku acīm tās var palikt neredzamas, tomēr mašīnmācīšanās algoritmi var palīdzēt atklāt šādu sistemātisku darbību modeļus.
Metodoloģija
Lai izmantotu šo pieeju, ir nepieciešama paraugu (uzņēmumu) izlase, kuru “patiesā” darbība ir zināma (izvairās no nodokļu nomaksas vai atbilst likuma prasībām), lai “trenētu” algoritmu, proti, palīdzētu tam mācīties, analizējot datus, identificēt gadījumus, kad notiek izvairīšanās no nodokļu maksāšanas.
Šajā pētījumā* tika izmantoti Valsts ieņēmumu dienesta (VID) rīcībā esošie uzņēmumu līmeņa dati, kuros ietverta informācija par visām VID veiktajām iedzīvotāju ienākuma nodokļa un sociālās apdrošināšanas iemaksu revīzijām laikposmā no 2013. gada līdz 2020. gada vidum.
Dati ir pilnībā anonimizēti. Tas nozīmē, ka pētniekiem nebija iespējas identificēt uzņēmumu nosaukumus vai reģistrācijas numurus.
No datos iekļautās informācijas bija zināms, vai revidētajam uzņēmumam audita rezultātā bija jāmaksā papildu nodokļi vai sods, kā arī uzņēmumu raksturlielumu un finanšu rādītāju kopums (piemēram, apgrozījums, aktīvi, peļņa), kas aptver gan revidētus, gan nerevidētus uzņēmumus, kuri darbojas Latvijā.
Pieņemot, ka gadījumā, ja uzņēmumā netiek uzrādīts viss izmaksātais atalgojums, auditori to, visticamāk, atklās, revīzijas rezultāti sniedz ticamu informāciju par uzņēmuma atbilstību noteiktajām nodokļu prasībām. Tātad var pieņemt, ka uzņēmumi, kuri ir saņēmuši sodu, piemēram, par krāpšanos ar iedzīvotāju ienākuma nodokli, ir izvairījušies no nodokļu nomaksas, savukārt tie revidētie uzņēmumi, kuri nav sodīti, atbilst likuma prasībām.
Algoritms mācās, kā atšķirt vienu uzņēmuma tipu no otra, balstoties informācijā, kas sniegta uzņēmumu bilancēs.
Trenējot algoritmu, mēs sadalām revidēto uzņēmumu izlasi divās daļās pēc nejaušības principa – mācību un testēšanas apakšizlasēs. Pirmā tiek izmantota, lai trenētu algoritmu, un rezultāti pēc tam tiek izvērtēti, balstoties uz otro, t. i., izmantojot datus, kurus algoritms iepriekš nav “redzējis”. Ja testēšanas apakšizlasē tiek uzrādīti apmierinoši rezultāti, algoritms ir izmantojams visam uzņēmumu kopumam, lai iegūtu aplēses par to, cik liels ir to uzņēmumu īpatsvars, kuri izvairās no nodokļu nomaksas.
Šajā pētījumā tika izmantoti trīs algoritmi, kas savstarpēji atšķiras ar veidu, kā tie mācās no datiem:
- Random Forest (“Gadījuma mežs”);
- Gradient Boosting (“Gradienta pastiprināšana”);
- Logit (“Loģistiskā regresija”).
(Lai gūtu ieskatu par mašīnmācīšanās metodēm, skat. Athey, Imbens (2019).) Katram algoritmam ir stiprās un vājās puses, tāpēc tika izmantotas un salīdzinātas vairākas pieejas.
Rezultāti
Vispirms testējām, cik labi algoritmi spēj atklāt uzņēmumus, kuri izvairās no nodokļu nomaksas, izmantojot testēšanas izlasi.
1. tabulā ir redzams trīs dažādu algoritmu modeļu sniegums.
Precizitāte ir pareizi klasificētā procentuālā uzņēmumu daļa (t. i., modeļa prognoze atbilst novērotā uzņēmuma tipam). Mūsu izlasē aptuveni 45% revidēto uzņēmumu bija jāveic papildu iedzīvotāju ienākuma nodokļa maksājumi un sociālās apdrošināšanas iemaksas. Tas nozīmē, ka “naivā pieeja”, kurā tiek pieņemts, ka visi uzņēmumi izvairās no nodokļu nomaksas, būtu precīza 45% gadījumu. Turpretī klasifikācija, kas pieņem, ka visi uzņēmumi godīgi maksā visus nodokļus, būtu pareiza 55% gadījumu.
Pēdējo skaitli var izmantot kā slieksni, lai novērtētu algoritmu sniegumu.
Vislabākais sniegums ir algoritmam Random Forest (“Gadījuma mežs”). Tas spēj pareizi klasificēt vairāk nekā 70% novērojumu, pārspējot “naivā sliekšņa” prognozes par vairāk nekā 15 procentpunktiem, kas ir būtisks uzlabojums. Gradient Boosting (“Gradienta pastiprināšana”) sniegums ir nedaudz zemāks, savukārt Logit (“Loģistiskās regresijas”) algoritmam ir zemākā precizitāte.
|
Random Forest |
Gradient Boosting |
Logit |
|
|
Precizitāte |
71,0% |
70,1% |
64,3% |
Avots: Autoru aprēķini
Tagad pievērsīsimies mūsu analīzes galvenajam jautājumam un novērtēsim uzņēmumu īpatsvaru, kuri izvairās no darbaspēka nodokļu maksāšanas, starp visiem Latvijas uzņēmumiem (uzņēmumiem, kurus VID nav revidējis).
Tā kā Random Forest (“Gadījuma meža”) algoritms pārspēja pārējos, arī šajā aspektā mēs koncentrējamies uz tā rezultātiem.
1. diagrammā ir atainots rezultāts. Kopumā aplēses rāda, ka uzņēmumu īpatsvars, kuri, visticamāk, izvairās no darbaspēka nodokļu nomaksas, ir ap 40%. Svarīgi piebilst, ka tas nenozīmē, ka 40% uzņēmumu Latvijā neuzrāda visu savu darbinieku algas, bet drīzāk norāda uz to, ka 40% uzņēmumu kaut kādā mērā notiek izvairīšanās no darbaspēka nodokļu nomaksas.
1. diagramma. Aplēstā daļa uzņēmumu, kuri izvairās no nodokļu nomaksas, % no visiem uzņēmumiem

Avots: Autoru aprēķini
Tomēr iegūtie novērtējumi par negodprātīgo uzņēmumu īpatsvaru var būt nobīdīti, jo ir (vismaz) divi faktori, kuri ietekmē novērtēto uzņēmumu īpatsvaru un kuru ietekme darbojas pretējos virzienos.
Pirmkārt, VID veic pārbaudes uzņēmumos, kuros tā vērtējumā ir augstāks izvairīšanās no nodokļu nomaksas risks. Piemēram, ja diviem uzņēmumiem ir identiski finanšu pārskati, bet tikai viens no tiem ir revidēts, tas, iespējams, ir tādēļ, ka VID rīcībā ir papildu informācija, kas mums nav zināma.
Savukārt tas nozīmē, ka mūsu algoritms abus uzņēmumus tomēr nevarēs atšķirt un pieņems kā ticamu, ka abi izvairās no nodokļu nomaksas. Šī problēma palielina to uzņēmumu īpatsvaru, kuri tiks novērtēti kā negodprātīgi, proti, izvairās no nodokļu nomaksas.
Otrkārt, algoritma pamatā ir uzraudzības iestāžu riska novērtējums, kas var nebūt precīzs.
Piemēram, dažas nerevidētu uzņēmumu grupas ar noteiktām pazīmēm, kas tomēr neatbilst likuma prasībām, iespējams, var izmantot izvairīšanās no nodokļu nomaksas shēmas, kuras uzraudzības iestādēm nav zināmas.
Izmantojot mūsu pieeju, šādas uzņēmumu grupas nevarēs atklāt, tādējādi samazinot novērtēto negodprātīgo uzņēmumu īpatsvaru. Līdz ar to iegūtās kopējās aplēses ir jāinterpretē piesardzīgi (tāpat kā jebkurš cits izvairīšanās no nodokļu nomaksas rādītājs).
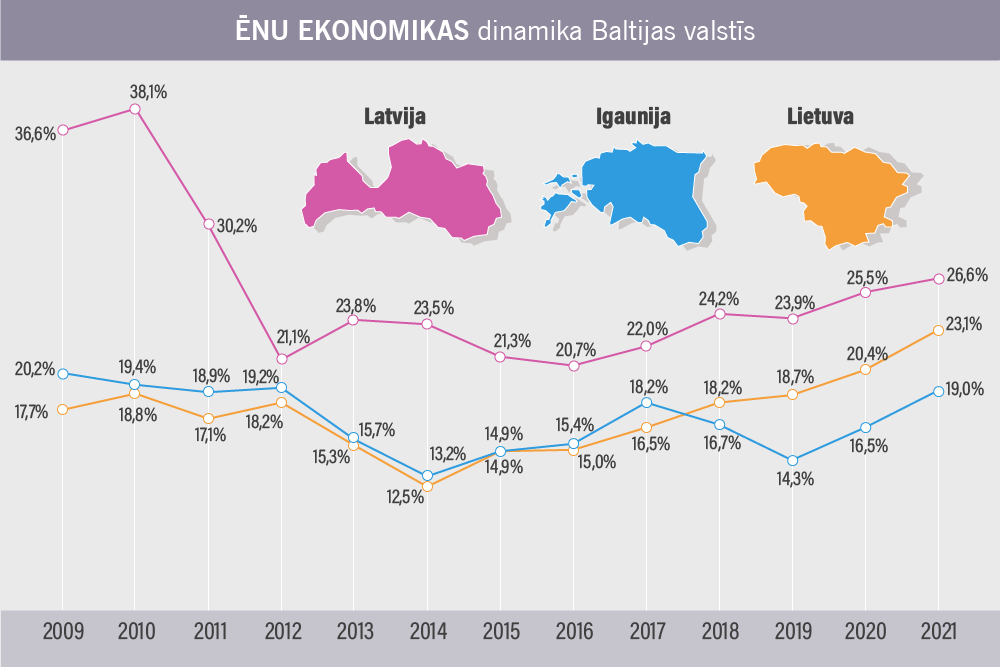
Aplūkojot iegūto datu attīstību vairākos gados, redzam nelielu U-veida tendenci: uzņēmumu īpatsvars, kuri izvairās no nodokļu nomaksas, samazinājās no 41,4% 2014. gadā līdz 39,5% 2017. gadā, taču pēc tam pieauga līdz 42,5% 2019. gadā. Šāda dinamika saskan ar Putniņa un Saukas (2022) pētījuma datiem, kuri liecina, ka no 2014. līdz 2019. gadam no nodokļu iestādēm slēpto algu kopējais īpatsvars Latvijā veidoja U-veida tendenci, sasniedzot 22,3% 2019. gadā.
Nobeiguma secinājumi
Pētījums parāda, ka mašīnmācīšanās paņēmienus var veiksmīgi izmantot, analizējot uzņēmumu administratīvos datus, lai atklātu tos, kuri, visticamāk, izvairās no (darbaspēka) nodokļu nomaksas.
Mašīnmācīšanās paņēmienus var izmantot papildus jau esošajai VID praksei, lai uzlabotu revidējamo uzņēmumu atlasi, palielinot iespēju atklāt tos uzņēmumus, kuri izvairās no nodokļu nomaksas.
Mūsu izvēlētā algoritma – Random Forest (“Gadījuma mežs”) – rezultāts pārspēj “naivo slieksni” par vairāk nekā 15 procentpunktiem, kas ir vērā ņemams uzlabojums. Kad šie rīki tiktu ieviesti, to pielietojums varētu uzlabot revīziju efektivitāti gandrīz bez papildu izmaksām.
Pētījuma rezultāti arī norāda uz daudzsološām iespējām uzlabot šādu metožu pielietojumu.
Mūsu ieteiktā algoritma prognozēšanas spēju uzlabojums tika panākts, izmantojot ierobežotu mainīgo kopumu, kas ir pieejams no uzņēmumu bilancēm. Ņemot vērā, ka VID rīcībā varētu būt pieejami detalizētāki uzņēmumu līmeņa dati, kurus ir liegts sniegt trešajai pusei, algoritmu darbību ir iespējams vēl vairāk uzlabot.
* Publikācija balstīta Latvijas Zinātnes padomes finansētās valsts pētījumu programmas “Ēnu ekonomikas mazināšana ilgtspējīgas ekonomikas attīstības nodrošināšanai” projekta “Ēnu ekonomikas izpēte Latvijā (RE:SHADE)” (Nr. VPP-FM-2020/1-0005) rezultātos.
Atsauces:
Athey, S., Imbens, G. W. (2019). Machine learning methods that economists should know about. Annual Review of Economics. 11, p. 685–725.
Cecchini, M., Aytug, H., Koehler, G. J., Pathak, P. (2010). Detecting management fraud in public companies. Management Science. 56, p. 1146–1160.
Putniņš, T. J., Sauka, A. (2022). Shadow Economy Index for the Baltic Countries, 2009–2021. Report. SSE Riga.
Ravisankar, P., Ravi, V., Rao, G. R., Bose, I. (2011). Detection of Financial statement fraud and feature selection using data mining techniques. Decision Support Systems. 50, p. 491–500.
West, J., Bhattacharya, M. (2016). Intelligent financial fraud detection: a comprehensive review. Computers & Security. 57, p. 47–66.